Kotlin DataFrame + Kotlin Kandy on GitHub Pages で構築するお手軽データ分析基盤
会社がお盆休みだったので、子育ての傍らで夜な夜な自由研究をしていた。
現在自分が見ているチームのことを分析するために GitHub や Jira など様々なデータソースを csv で取得をしている。
これまでは内部利用向けのデータベースなどに csv からデータを投入して、それを self host した Metabase 経由でデータを見るなどかなりお手製でやっていた。
この方法でも一定ワークしてたものの、それなりに手作業があり若干困っていた。
何かしらの SaaS ツールを使うなどの選択肢ももちろんあるしそれが可能であればそうするのが良いと思うが (e.g. Findy Team+ など) 、今回は個人でしか利用していないこともあり、もっとコスト低く実現したかった。
また可能であればインフラの管理やソフトウェアのバージョンアップなども面倒なので避けたいというのが本音である (如何せん個人でしか利用していないので)。
そこで結論からにはなるが、Kotlin DataFrame と Kotlin Kandy を利用して、以下のようなソリューションに至った
ちなみに上記の方法で、「過去 Pocket で読んだ記事数の累計を月ごとに集計」を公開したものが こちら で見ることができる。
見た目としては以下のようなページとなっている。
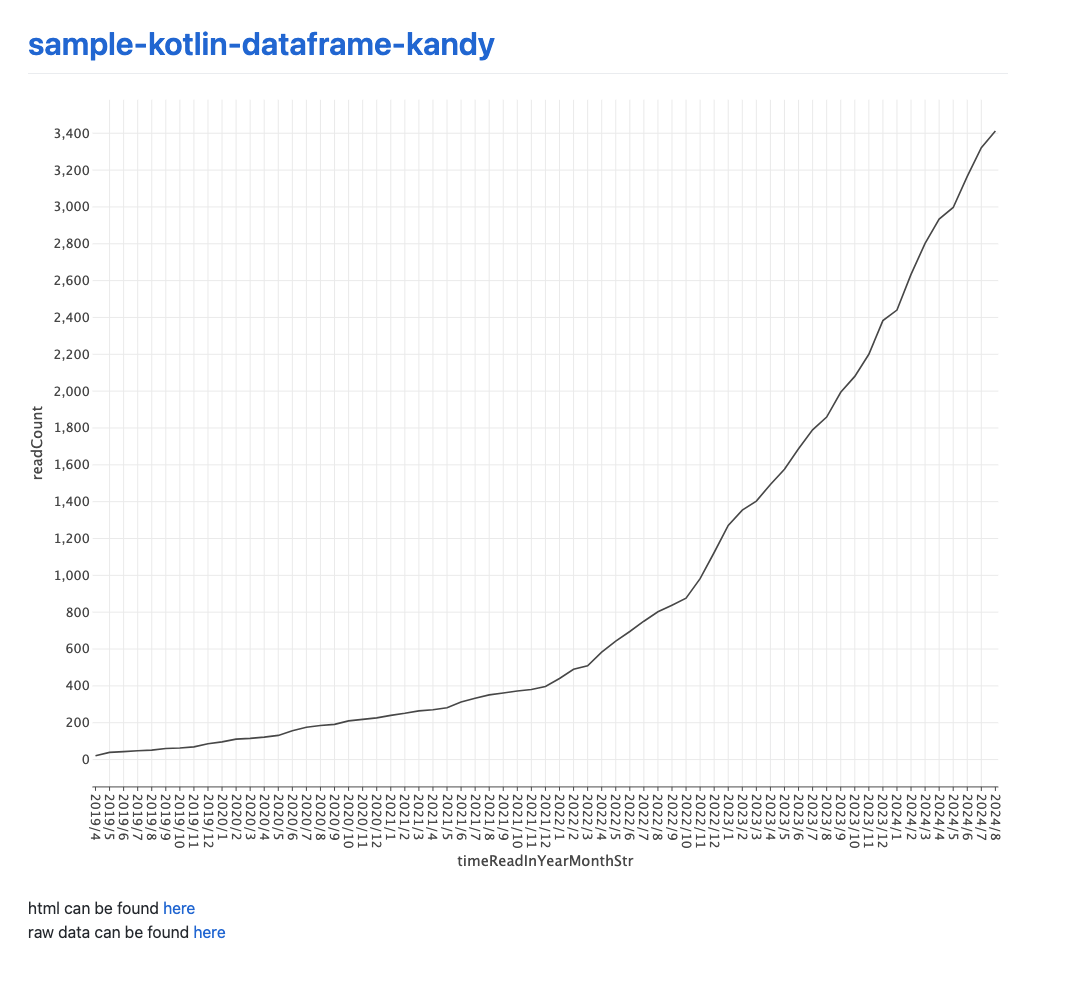
ソースコードなどについても omuomugin/sample-kotlin-dataframe-kandy で公開している。
GitHub Pages は GitHub.com で利用すると Private リポジトリだった場合でもアクセスそのものはデフォルトで public になってしまうので、制限したい場合には、カスタムドメインの設定を行い IP 制限などを行うなどする必要があるので注意を。
今回の自分のケースの場合には、 GitHub Enterprise を利用しているため適切なアクセス制限などがなされている。
参考: GitHub Pages サイトの可視性を変更する
この記事では、そもそも Kotlin DataFrame だったり、 Kotlin Kandy の事例がなかったりもしたので自分用にもメモとして残しておく。
そもそも Kotlin DataFrame や Kotlin Kandy とは何か
Kotlin版pandas !? Kotlin Dataframeを使ってデータ分析 などでも紹介されているので、詳細はそちらを読んでもらうとして、自分の雑な理解では pandas など Python や R で行われていたようなデータ分析を Kotlin でできるようにしたものだと認識している。
特に Kotlin DataFrame はデータ分析、Kotlin Kandy はデータの可視化のためのライブラリ (もはやフレームワーク?) という理解をしている。
(自分的としての) 最大の特長としては、以下2つである
- 慣れている Kotlin で書けること
- Jupyter Notebook などがなくても gradle などで JVM アプリケーションとして動作できること
特に後者は GitHub Actions などで自動実行するなどを考慮すると、手軽に gradle などで手軽に実行できて嬉しい。
もしかすると簡単に Jupyter Notebook を Docker などで動作させる方法があるのかもしれないが、どうやら Kotlin Kernel などが必要らしくそれ以上は掘れていない。
詳細
データ収集
各種データソースから分析に必要な csv を取得する。
これは curl でも何かしらの API client でもなんでも良い。
今回は取得したデータを src/main/resource に格納している。
データ分析 (準備)
ここでは、 Kotlin DataFrame を利用する。
最も単純な例としては以下のようなコードで表現される。
val dataframe = PocketArchiveDataFrame.load()
object PocketArchiveDataFrame {
object Column {
val id by column<String>()
val favorite by column<Int>()
val timeAdded by column<Long>()
val timeRead by column<Long>()
}
fun load(): DataFrame<*> {
return DataFrame.readCSV(
"src/main/resources/pocket_archive.csv",
delimiter = ',',
header =
listOf(
Column.id.name(),
Column.favorite.name(),
Column.timeAdded.name(),
Column.timeRead.name(),
),
colTypes =
mapOf(
Column.id.name() to ColType.String,
Column.favorite.name() to ColType.Int,
Column.timeAdded.name() to ColType.Long,
Column.timeRead.name() to ColType.Long,
),
)
}
}
メモリにロードされたデータは DataFrame というオブジェクトであり、 Operations でも紹介されているように様々な操作が可能である。
例えば、カラムを追加したり、カラムの値を加工したり、集約などを行ったり、複数の DataFrame を join したりなど。
細かい Tips として PocketArchiveDataFrame にもあるように
header: それぞれのカラム名を定義することができるcolTypes: 通常デフォルトでreadCSVを利用すると自動で型が推測されたりするが、誤ったものなどが多かったりもするので自分で定義することも可能
ちなみに dataframe.schema() で読み込まれた型情報などを出力することもできる。
dataframe.schema()
// ->
// id: String
// favorite: Int
// timeAdded: Long
// timeRead: Long
また by column<String>() のような記述が馴染みがないと思うが、これはいくつかあるカラムへの参照の仕方の1つで Column accessors API と呼ばれるものである。
他にも String API と呼ばれるアクセス方法もあり "column_name"<String>() のように記述できる。
他の参照方法についても Access API で読むことができる。
(中には、Extension properties API のように Jupter Notebook でしか利用できないようなものもある)
データ分析
メモリ上に DataFrame をロードしたあとは様々な Operations を通して可視化に向けてデータの加工をしていく。
コードとしては一番込み入った箇所になる上に SQL っぽさもあり若干読みづらい部分があるが仕方ないものとして一旦今は受け入れている。
private val timeReadInDateTime by column<LocalDate>()
private val timeReadInYear by column<Int>()
private val timeReadInMonth by column<Int>()
private val timeReadInYearMonthStr by column<String>()
private val readCount by column<Int>()
val result =
dataframe.add(timeReadInDateTime) { // -> データを参照し加工をした上でカラムとして追加する
ZonedDateTime.ofInstant(Instant.ofEpochSecond(PocketArchiveDataFrame.Column.timeRead()), ZoneId.of("UTC"))
.withZoneSameInstant(ZoneId.of("Asia/Tokyo")) // -> JST にした上で YYYY-MM-dd に加工する
.toLocalDate()
}.add(timeReadInYear) {
timeReadInDateTime().year
}.add(timeReadInMonth) {
timeReadInDateTime().monthValue
}.add(timeReadInYearMonthStr) { // -> 表示用としてカラムを用意する
"${timeReadInDateTime().year}/${timeReadInDateTime().monthValue}"
}.select { // -> これまで得た `Dataframe` から必要なものだけを `select` する
timeReadInYear and
timeReadInMonth and
timeReadInYearMonthStr
}.groupBy { timeReadInYear and timeReadInMonth and timeReadInYearMonthStr }
.sortBy { timeReadInYear and timeReadInMonth }
.aggregate { count() into readCount }
.cumSum { readCount }.concat() // -> `cumSum` は累計和の関数で "org.jetbrains.kotlinx:kotlin-statistics-jvm:x.x.x" を必要とするので注意
とまあ上記のように様々な Operations を通して最終的に可視化するための DataFrame を作っていく。
他にも複数の DataFrame を扱う Mutiple DataFrames があったり、これは Kotlin Kandy の話を先取ってしまうが、複数のグラフを1つのグラフとして描画する方法も紹介されていたりする Series Hack。
ちなみに可視化まで含めると後でも紹介するが Examples を見ると非常に参考になる。
データ可視化
ここでは、Kotlin Kandy が活躍する。
今回は、以下のようなコードで可視化を実行している。
val plot =
result.plot {
line {
x(timeReadInYearMonthStr)
y(readCount)
}
layout {
size = 1000 to 800
}
}
また、これだけでは実際にファイルなどには保存されず以下のように保存することになる。
Export to File にもあるように、 PNG、SVG、HTML 形式で保存することができる。
plot.save(filename = "${this::class.java.simpleName}.svg", path = FilePathHelper.docImagesPath())
plot.save(filename = "${this::class.java.simpleName}.html", path = FilePathHelper.docHTMLPath())
object FilePathHelper {
fun resourcePath() = "src/main/resources"
fun docImagesPath() = docBasePath() + "/images"
fun docHTMLPath() = docBasePath() + "/html"
fun docRawPath() = docBasePath() + "/raw"
private fun docBasePath() = Path(System.getProperty("user.dir"), "docs/plot").toString()
}
様々なグラフをどうやって可視化するかついては、前節でも紹介したが Examples を見ると非常に参考になる。
公開
今回冒頭にも書いた通り、インフラの管理などを極力したくなかった + なるべくお手軽に可視化したいというのがモチベーションだった。
そこで GitHub Pages で Markdown ファイルをホスティングする形を取ることにした (というかこれができることが目的だったので順番として最初に思いついてたのだけど)。
余談として HTML などにしなくても GitHub Pages では Markdown を置くだけでいい感じに表示してくれるのでお手軽さ的には大変便利である。

html can be found [here](./plot/html/SampleTask.html)
raw data can be found [here](./plot/raw/SampleTask.html)
で最終的に表示されたのが https://omuomugin.github.io/sample-kotlin-dataframe-kandy/ となっている
ちなみに GitHub Pages は GitHub.com で利用すると Private リポジトリだった場合でもアクセスそのものはデフォルトで public になってしまうので、制限したい場合には、カスタムドメインの設定を行い IP 制限などを行うなどする必要があるので注意を。
今回の自分のケースの場合には、 GitHub Enterprise を利用しているため適切なアクセス制限などがなされている。
参考: GitHub Pages サイトの可視性を変更する
まとめ
以上の仕組みにより、以下2つを手動ないしは GitHub Actions などで自動化すればお手軽データ分析基盤として機能する (と思っている)
- csv などのデータ収集
./gradlew startの実行と変更されたファイルのコミット